![banner]()
![Orion-14B]()
Born for Enterprise Applications
Born for Enterprise Applications
Effective, Affordable, Reliable
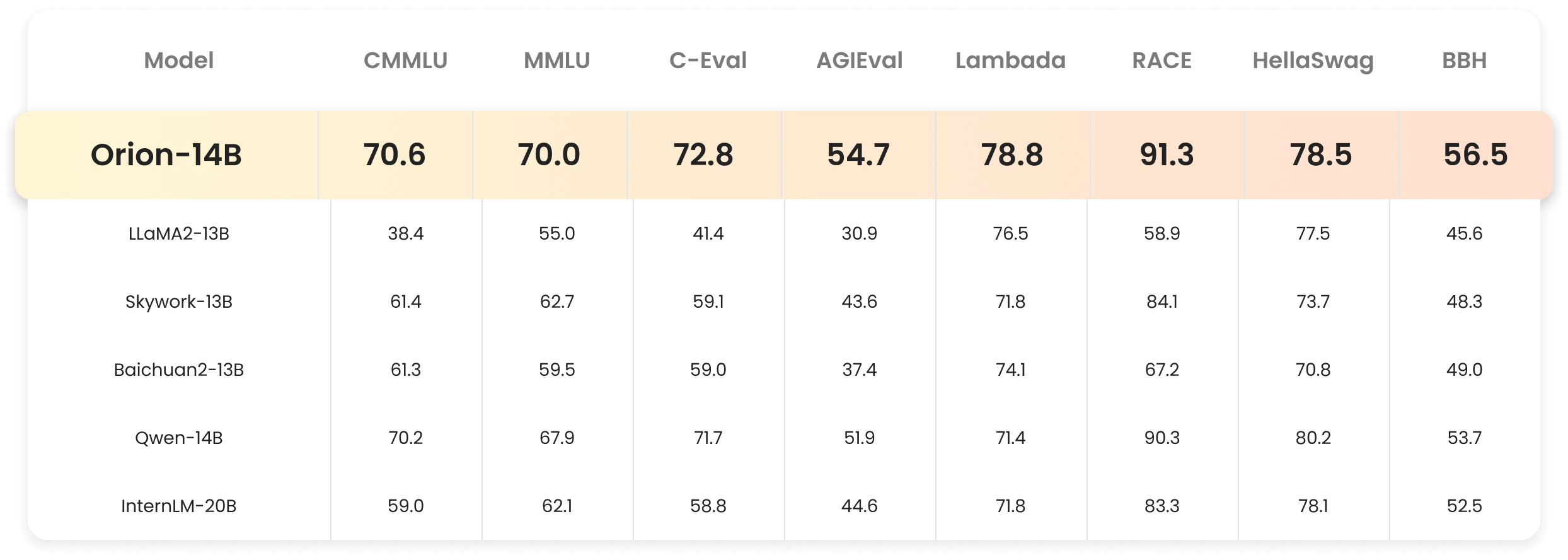
Evaluation Metrics
![OrionStar Open-Source Multilingual Large Language Model,Orion-14BEvaluation Metrics]()
Based on the independent evaluation results from the third-party agency OpenCompass.
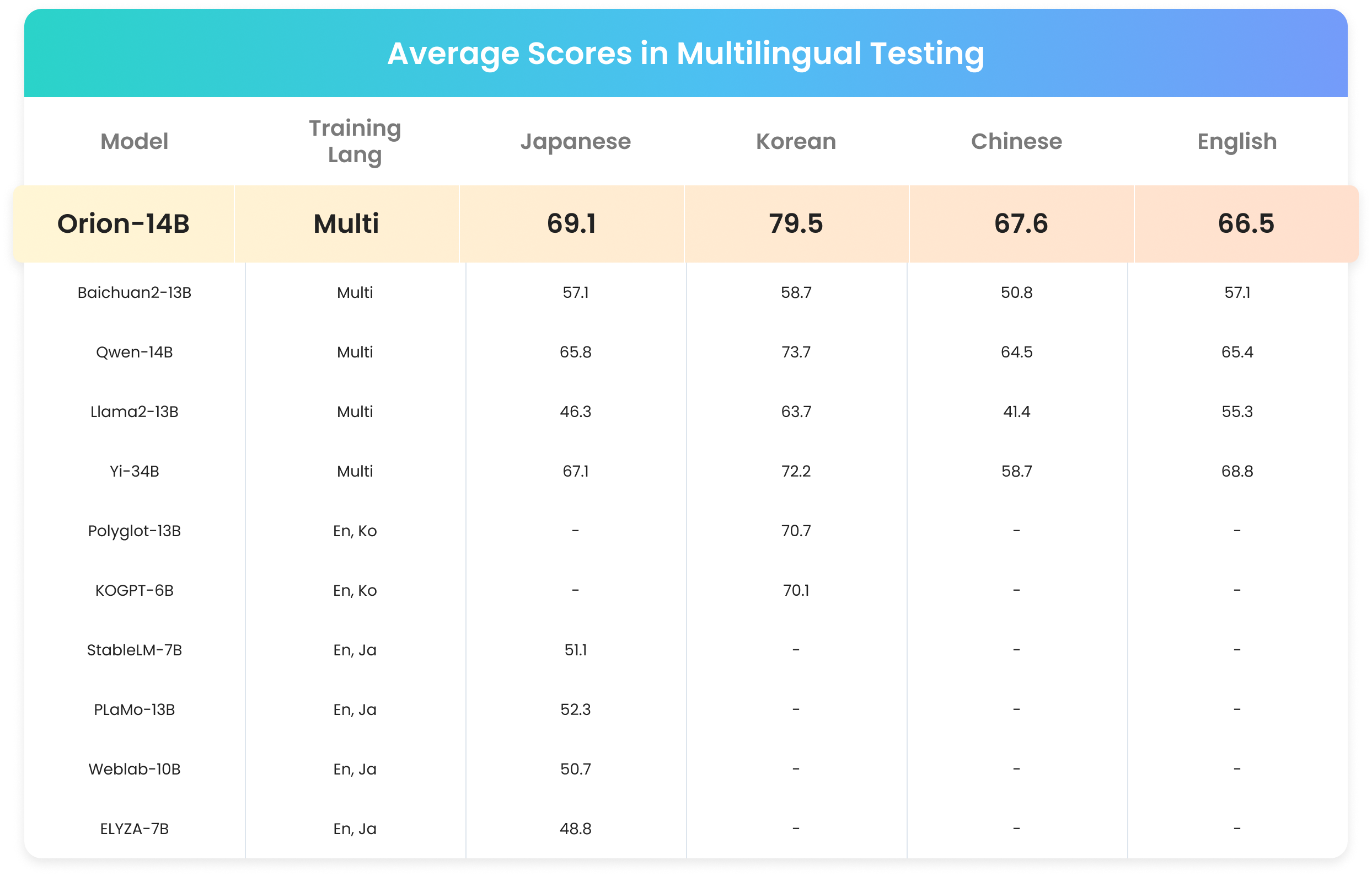
Multiple Language Test Scores
![OrionStar Open-Source Multilingual Large Language Model Evaluation Metrics]()
Performance Highlights
Rival hundred-billion-parameter models
The 14B LLM, a medium-scale model, achieves state-of-the-art performance comparable to models below 20B.
Support 320K ultra-long context
Support extremely long texts, performing exceptionally well at a token length of 200k and can support up to a maximum of 320k.
The optimal LLM choice for enterprises
- Orion-14B series fine-tuned LLM, adaptable to various scenarios
- Performance loss after INT4 quantized is less than 1%
Strong multilingual capabilities
Ranked first in evaluations for Chinese, English, Japanese, and Korean among models with parameters below 20B.
Technical Advantages
![Top Team]()
Top Team
More than a hundred top algorithm scientists from global tech giants such as Facebook, Yahoo, Baidu, and more.
![Algorithm Mastery]()
Algorithm Mastery
Our technical roadmap encompasses DNN, attention, Bert, LLM, ASR, TTS, NLP, tracking the industry's technological evolution comprehensively.
![Scene Understanding]()
Scene Understanding
Adapted for applications in over a thousand enterprises.
![Application Refinement]()
Application Refinement
Extensive experience in refining applications for a user base of 2 billion globally.
![Data Accumulation]()
Data Accumulation
Accumulated real user query data in the tens of billions and token data in several tens of trillion over nearly 7 years.
Highly Effective Enterprise-Application LLM
Orion-14B series fine-tuned large language models:
professional scenario capabilities, state-of-the-art ten-billion-parameter models
![General dialogue fine-tuning]()
General dialogue fine-tuning
Among open-source multilingual large language models below 20B, the best-performing general dialogue model.
![Plugin fine-tuning]()
Plugin fine-tuning
Enhanced capabilities in Agent, ReAct, and Prompting, delivering results close to a hundred billion parameter models.
![RAG fine-tuning]()
RAG fine-tuning
Knowledge boundary control, precision in answers, achieving effects similar to trillion-parameter models.
![Long Token fine-tuning]()
Long Token fine-tuning
Supports tokens of up to 320K in length, the best among open-source models in token support.
![Knowledge extraction fine-tuning]()
Knowledge extraction fine-tuning
Transforms unstructured data into structured data.
![Question-Answer Pair Generation fine-tuning]()
Question-Answer Pair Generation fine-tuning
Generates question-answer pairs while ensuring comprehensive knowledge coverage.
![Japanese and Korean fine-tuning]()
Japanese and Korean fine-tuning
Optimal performance in Japanese and Korean languages among open-source models below 20B.
Orion-14B Large Language Model
Affordable LLM for Enterprise Applications
![Suitable for Enterprise Use]()
Suitable for Enterprise Use
After INT4 quantization, the model size is reduced by 70%, inference speed is increased by 30%, with less than 1% performance loss
![Run on Affordable Graphics Cards]()
Run on Affordable Graphics Cards
Such as NVIDIA RTX 3060, capable of achieving 31 tokens per second, approximately 100 characters
![<span>Affordable</span> LLM for Enterprise Applications]()
Affordable LLM for Enterprise Applications
![Suitable for Enterprise Use]()
Suitable for Enterprise Use
After INT4 quantization, the model size is reduced by 70%, inference speed is increased by 30%, with less than 1% performance loss
![Run on Affordable Graphics Cards]()
Run on Affordable Graphics Cards
Such as NVIDIA RTX 3060, capable of achieving 31 tokens per second, approximately 100 characters
![<span>Affordable</span> LLM for Enterprise Applications]()
Reliable LLM for Enterprise Applications
![Private Deployment]()
Private Deployment
Large model servers can be situated within the enterprise intranet, ensuring all data does not connect to the public internet.
![Free, Open Source, and Commercially Usable with Community Technical Support]()
Free, Open Source, and Commercially Usable with Community Technical Support
Available for download from communities such as Hugging Face and GitHub.
![<span>Reliable</span> LLM for Enterprise Applications]()